

Roland Berger is the partner of choice to successfully navigate the TMT industry's complex market dynamics.

Watt’s up in AI: reshaping the data center value chain
By Michael Knott, Tim Longstaff, Geoff Versteeg and Siyi Hao
How GPUs will create new winners and losers in engineering
Conventional wisdom suggests that the AI data center boom could usher in a new golden age for engineering products and services. While it is true that the rapid growth of data centers is expected to drive demand of up to USD 380 billion by the end of the decade, this will not be a rising tide that lifts all boats. Instead, two inherent characteristics of GPUs — their power density and power variability — require a fundamental rethinking of the products and services that support these new AI factories. This disruption is likely to create a new set of winners and losers.

"Our forecast is close to USD 380 billion in demand from data centers for engineering products and services by 2030."

In this article, we outline the most plausible trajectory for data center demand over the rest of the decade — and what it could mean for transformers, uninterruptible power supplies (UPS), cooling systems, and a range of other engineering products and services. The takeaway: the current product catalog is no longer fit for purpose, creating fertile ground for high-growth challengers. Incumbents have a short window to act before they face their innovator’s dilemma. Investors must become more technology-focused to fully understand the risks and opportunities.
Even in our “GPU supply-constrained” scenario, data centers are projected to require USD 380 billion in engineering products and services by 2030.
Buoyed by breakthroughs in large language models (LLMs), the press is filled with breathless articles about the deployment of new AI factories. At Roland Berger, our central forecast identifies two key manufacturing constraints for data centers: NVIDIA and TSMC.
Our base-case forecast for data center CPUs and GPUs are 212 GW by 2030. This is constrained by TSMC’s CoWoS (Chip on Wafer on Substrate) advanced packaging capacity.This estimate excludes on-premise servers, which are generally less addressable by engineering suppliers. Since approximately 50% of servers remain on-premise in many markets, our figures are significantly lower than those of other forecasts.
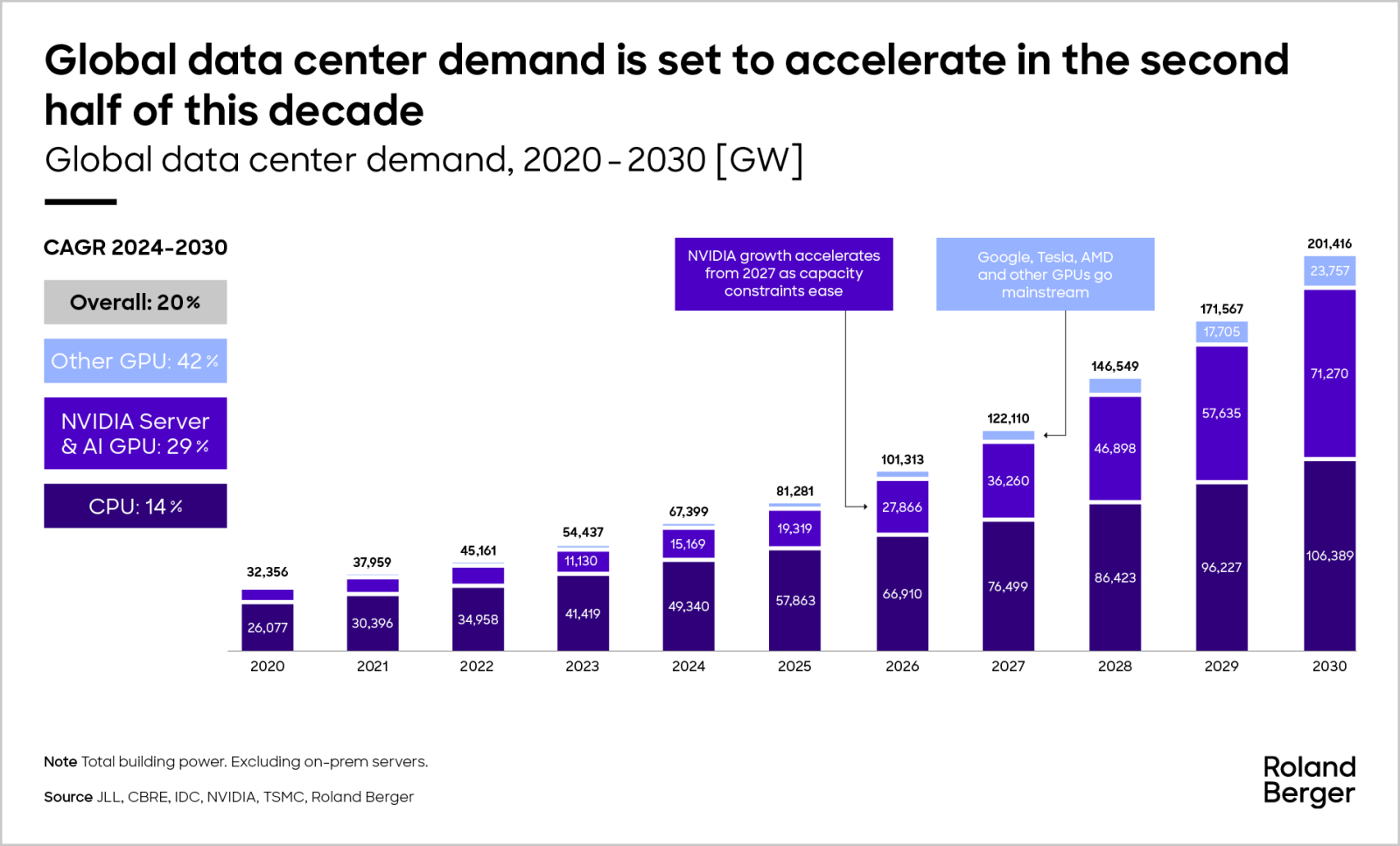
To put these numbers in perspective, in 2030 alone, the industry will add around 34 GW of incremental capacity — more than the cumulative build before 2021.
Our forecast accounts for known supply constraints in the semiconductor supply chain, though this is evolving as investment increases. Our “fab acceleration” scenario reflects the potential impact of additional investment by Broadcom, Intel, and others by 2030. Similarly, other supply-side constraints — primarily grid capacity — could result in slower growth.

The tide is rising, but not evenly: GPUs have more demanding cooling requirements. This makes a gigawatt (GW) of GPU data center capacity more expensive to build than a GW of CPU data center capacity.

This combination of rising demand and increasing cost per GW results in a base case of USD 381 billion in annual demand by 2030, growing at a 15% CAGR.
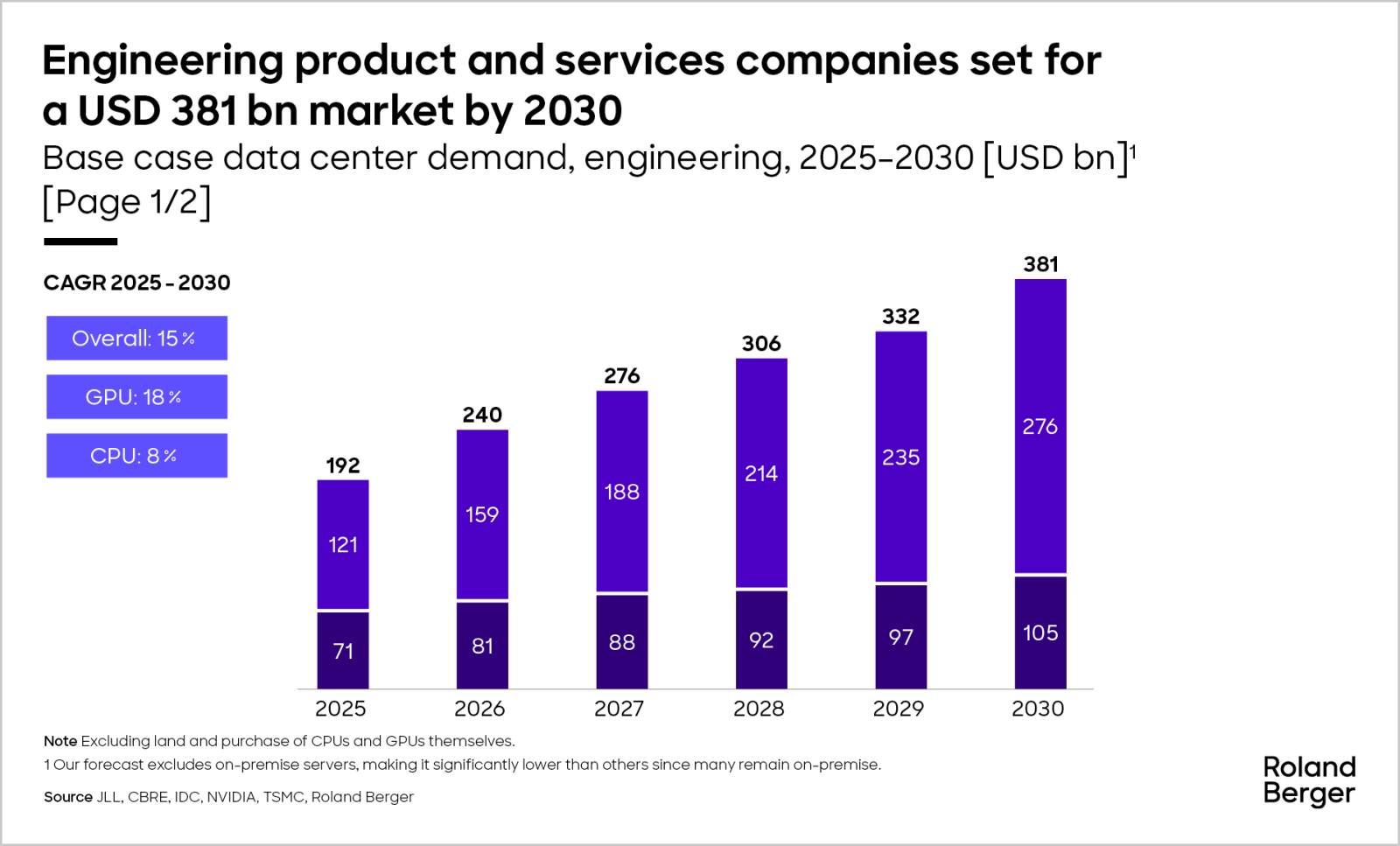
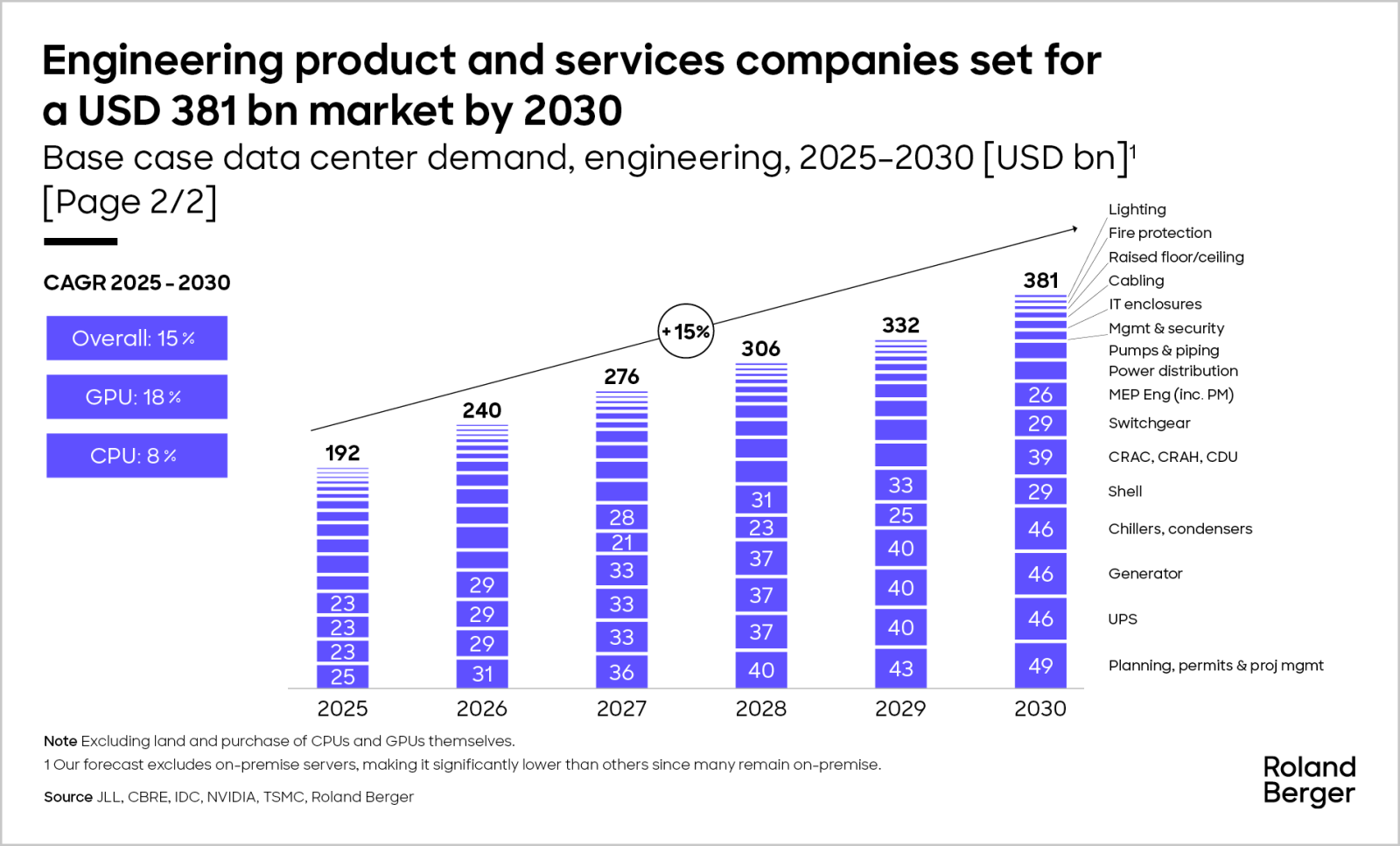
"The tide of AI data center growth is rising, but it’s uneven. Winners will be those who rethink the fundamentals."

The engineering sector and its investors are understandably intrigued by the growth opportunity — and rightly so. Even previously unglamorous components, such as crankshafts, are likely to experience once-in-a-generation growth. But a word of caution: the new data center demand is not the same as the old demand. This is not “more of the same.” GPUs are not CPUs, and this distinction matters for the engineering sector and its investors.
Power density
The training of LLMs often uses distributed training techniques, such as data parallelism and model parallelism, which coordinate computation across thousands of GPUs. This approach generates a substantial volume of traffic within the data center, as servers housing these GPUs frequently exchange model parameters - including weights and gradients - to maintain synchronization and ensure coherent learning.
Traditional CPU data center architectures were primarily designed and optimized to handle traffic between end users and the servers within the data center. However, the emergence of GPUs has required a fundamental shift in focus, prioritizing and optimizing in-building communication to effectively support the demands of distributed training workloads for LLMs.
Even seemingly minor delays in data transfers - often referred to as tail latency, which represents the latency experienced by the slowest data packets in a system - can have a disproportionately large impact on the overall efficiency of AI training jobs. These small delays can compound over time, leading to significant increases in job completion times and reduced effective utilization of valuable GPU resources, as some nodes must wait for straggling packets before synchronization can occur.
Given the inherent sensitivity of AI and machine learning (ML) algorithms, especially in the context of training large-scale models like LLMs, data center architectures are often designed with the primary goal of keeping GPU servers in close physical proximity to minimize communication delays and optimize training efficiency. Estimates suggest that a significant portion of the total time required to train these large-scale AI models can be directly attributed to network latency, highlighting the critical importance of minimizing these delays through careful data center design and layout.
This is not a technical side note — it explains why increasing rack density is inevitable. While CPU racks have typically operated at around 7 kW, growing roughly 10% per year, GPU racks are already approaching 250 kW. NVIDIA’s roadmap even envisions 1,000 kW (or 1 MW) in a single rack. This shift renders traditional CPU cooling technologies insufficient and opens the door to disruptive innovations such as liquid cooling.
"Incumbent vendors face the innovator’s dilemma, while challengers and investors have a narrow window to shape the next generation of winners and losers."

Power variability
The second core challenge is power variability. The central issue in GPU power management lies in balancing peak performance when demanded with minimal power draw during low-load conditions, creating a dynamic optimization problem. Aggressive power-saving measures can hinder performance, while unmanaged performance can lead to excessive power consumption, heat generation, and system instability. The increasing complexity and transistor density of modern GPUs, despite continuous advances in manufacturing process nodes, contribute to higher overall power consumption, making this challenge increasingly urgent.

"The surge in GPU-powered data centers isn’t just about more computing – it’s a rethink of transformers, UPS, and cooling, with the old supply chain struggling to keep up."

Existing CPU data center architectures were never designed to handle this level of variability, which means much of the current engineering products are no longer fit for purpose. Traditional transformers/grids, UPS systems, and backup batteries lack the responsiveness required for this new level of variability. Many of the most disruptive opportunities arise from this: solid-state transformers, lithium-ion batteries, Diesel Rotary UPS (DRUPS), and software-driven UPS systems are all examples of how existing architectures, products, and vendors face real risk of disruption.
Additionally, combined with rapidly increasing energy demand and grid connection constraints, data centers are increasingly deploying dedicated energy equipment. This can range from front-of-the-meter (FTM) renewables or large combined-cycle gas turbines (CCGTs) to behind-the-meter (BTM) equipment, which can include a combination of open-cycle gas turbines (OCGTs), reciprocating engines, and battery energy storage systems (BESS), among others.
Balance of plant
We observe linear, evolutionary responses from the incumbent supply chain as it attempts to meet the enormous disruption posed by high-value, unprecedentedly high-power, high-frequency hyperscalers, and note that this will lead to material disruption:
- Where data centers previously installed large diesel generators for standby power, this is no longer practical. Clients are now specifying as many as 100 large reciprocating engines for energy centers, each as big as a bus. Supply chain pinch points, for example crankshafts over 2 MW, meaningfully constrain the global ability to continue this linear approach.
- Cooling loads and direct liquid cooling account for a large proportion of data center power demand. An undergraduate engineer, wary of the timeline for small modular reactors (SMRs), might advocate a large gas turbine paired with a large absorption chiller. However, no such chiller is reliably available at this scale, and turbine OEMs have been surprised by this new demand, now facing five-year waiting lists.
- Climate change and air quality regulations will be stretched to the breaking point. We are already seeing laws change to allow more polluting gas as primary power in Dublin, and the mandatory use of waste heat in district heating loops in Germany.
- Very short-term demand fluctuations — the kind unconstrained GPU optimization requires — place enormous stress on the technology readiness of transformers, whether conventional or solid-state, as well as on power electronics. Zeitgeist batteries may give way to “science-past” solutions (e.g., synchronous condensers) or “science-future” solutions (e.g., supercapacitors) for these high-power, short-duration applications. The immediacy and high value of this demand are likely to drive rapid technology breakthroughs.
We would like to thank Gary Taylor for co-writing this article. Connect with Gary Taylor on Linkedln .
Sign up for our newsletter
Further readings

-(1)_tile_teaser_h260.jpg?v=1687234)
_tile_teaser_h260-2.jpg?v=1687234)





